배민 VOC 분석을 위한 토픽 모델링 공부 진행 중입니다:)
토픽 모델링 기법 중 가장 유명하고 많이 쓰이는 LDA에 관해 알아보겠습니다.
*본 노트는 고려대학교 산업경영공학부 DSMA 연구실의 LDA 관련 유튜브 영상을 참고했음을 밝힙니다.
LDA 문서 생성 프로세스(Document Generation Process)
지난 포스트에서 토픽 모델링은 문서 생성 프로세스에 대한 가정이 존재한다고 말씀드렸습니다.
LDA의 문서 생성 프로세스를 요약하자면 다음과 같습니다.
- 모든 문서들(Documents)은 여러 개의 토픽들을 가지고 있습니다.
- 각 토픽은 단어들의 분포입니다.
- 예를 들어, 아래 노란색 토픽의 경우 gene, dna, genetic 등의 단어들로 이루어져 있고, 각 단어마다 발생빈도는 다릅니다.
- 문서 집합이 동일하다면 각 문서의 토픽의 비중은 변하지 않습니다.
- 예를 들어, 내가 보고 있는 특정 문서에 포함된 토픽의 비중이 토픽1은 30%, 토픽2는 60%, 토픽3은 10%라면 이 비중은 변하지 않습니다.
- 문서 내 각 단어들은 이러한 토픽들로부터 샘플링됩니다(뽑힙니다).

자, 그런데 위에 것들은 말씀드렸듯 모두 '가정'입니다. 우리의 손에 쥐어진 것은 문서들(데이터)입니다. 이 데이터를 활용해서 아래 세 가지를 추론하는 것이 우리가 해야할 일입니다.
Q1) 각 토픽별 단어 분포
Q2) 각 문서별 토픽 분포
Q3) 각 문서의 각 단어는 어느 토픽에서 뽑힌 것인가

LDA 구조 자세히 뜯어보기
아래 그림은 LDA의 구조를 도식화 한 것인데요, 하나하나 뜯어보겠습니다.
먼저 각 노드들은 확률 변수를 의미하며, 화살표는 dependence(자세한 의미는 조금 뒤에 설명하겠습니다)를 의미합니다.
다음으로 주황색의 D 박스는 모든 문서에 대해 반복된다는 의미이고, 파란색 K 박스는 모든 토픽에 대해 반복된다는 의미입니다. D 박스 내에 있는 N 박스는 모든 D에 대해 적용되면서 동시에 각 문서의 모든 단어들에 대해 반복된다는 의미입니다(이중 for문을 생각하시면 됩니다).
Dirichelet parameter인 alpha와 Topic hyperparameter인 beta는 모두 Dirichlet 분포의 하이퍼 파라미터입니다.
alpha 노드로부터 theta_d 노드로 화살표가 이어져있지요? 앞서 말씀드렸듯 화살표는 dependence를 의미하는데,
각 문서들의 토픽별 분포가 alpha를 하이퍼 파라미터로 가지는 Dirichlet분포에서 나왔다는 것을 의미합니다.
마찬가지의 논리로 pie_k의 경우, 각 토픽의 단어 분포가 beta를 하이퍼 파라미터로 가지는 Dirichlet분포에서 나왔다는 것을 의미합니다.
다음으로 z(d,n)은 d번째 문서의 n번째 단어가 추출된 토픽을 의미하는데, theta_d로부터 나온 화살표가 z(d,n)를 가르키고 있으므로 '각 문서별 토픽 비중이 결정된 상황에서 z(d,n)은 뭐냐?'로 해석할 수 있습니다.
마지막으로 w(d,n)은 d번째 문서의 n번째 단어인데, z(d,n)과 pie_k가 주어진 상황에서 d번째 문서의 n번째 단어를 의미합니다.
(아래 사진의 우측 수식을 보는 것이 더 직관적으로 이해가 되는 것 같습니다)


위에서 말한 Q1, Q2, Q3에 대한 답을 찾기 위해서는 아래 가능도를 최대화하는 파라미터를 추정하면 됩니다. 아래 가능도는 바로 위에서 말한 LDA 구조도에서 나온 것이구요(결합 확률 분포이죠).
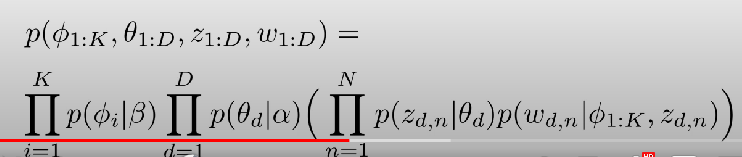
참고
-------
https://www.youtube.com/watch?v=WR2On5QAqJQ
'🥐데이터분석' 카테고리의 다른 글
| [토픽모델링] 논문 2개 리뷰; 스마트TV & OTT 온라인 리뷰 데이터 관련 (0) | 2022.06.14 |
|---|---|
| [배민 앱 VOC분석] 리뷰 군집화/클러스터링(예행연습) (0) | 2022.06.08 |
| [토픽 모델링] 기본 개념 이해하기 😎 (0) | 2022.06.06 |
| 다중회귀분석 R-squared 가 낮아도(0.2, 0.3) 괜찮을까? (0) | 2021.09.14 |
| 분류모델 성능평가 지표 : Confusion Matrix (0) | 2021.09.11 |