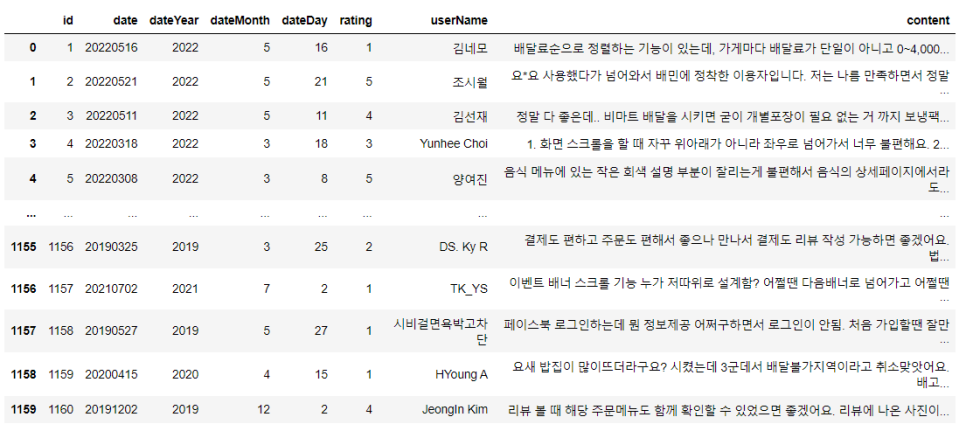
오늘은 배민 앱 VOC 데이터 분석을 통해 CAM(Customer Action Map)을 만들고, 이를 바탕으로 제품 개선안을 도출하는 과정의 첫 단계!
구글 앱 스토어에서 크롤링 한 데이터 중 일부를 활용해 리뷰 데이터를 군집화 해보겠습니다 :)
[진행 순서]
✅ 구글 앱 스토어에서 배민 리뷰 데이터 크롤링하기
✅ 토큰화(Tokenization)하고 명사만 추출하기
✅ 벡터화(Vectorization)하기
✅ 클러스터링을 통해 유사한 데이터끼리 묶기

구글 앱 스토어에서 배민 리뷰 데이터 크롤링하기
참고) https://heytech.tistory.com/293
Heytech 블로그에 있는 웹 크롤러 코드를 활용해 우선 전체 리뷰 데이터 중 1만 개 정도에 대해서만 크롤링을 진행했습니다. (리뷰가 총 22만개가 있어서 적어도 다섯 시간 정도는 소요될 것 같기 때문에 먼저 작게 시도를 해보고, 오늘 밤에 크롤링을 걸어두려고 합니다) 제공받은 코드 중 일부만 수정을 했고, 나머지는 거의 그대로 활용했습니다(Tony park 님 감사합니다🙏).
토큰화(Tokenization)하고 명사만 추출하기
-작성 대기-
벡터화(Vectorization)하기
참고) https://www.youtube.com/watch?v=meEchvkdB1U
- TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF는 TF가 가진 한계를 극복한 텍스트 데이터 벡터화 기법입니다.
TF는 Term Frequency, 즉 각 용어/단어가 문서(document)에 얼마나 자주 등장했는지, 용어별 빈도를 측정합니다.
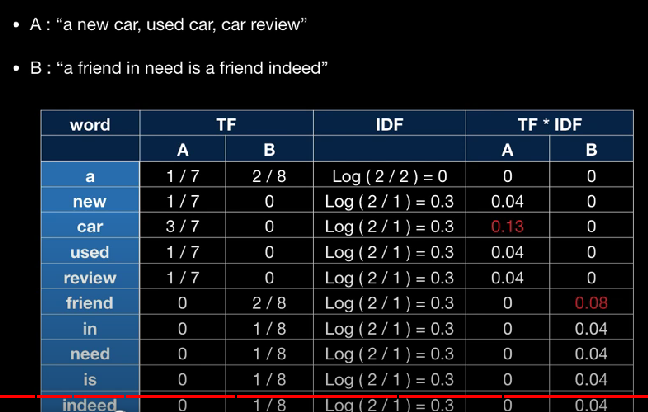
예를 들어, "a new car, used car, car review"라는 문서가 있습니다.
이 문서에는 총 7개의 단어가 등장하는데, car는 총 3번 등장했으니 TF는 3/7으로 문서 내 단어에서 가장 큰 값을 가지게 됩니다.
우리의 목적은 각 문서를 대표하는(문서와 더 연관성이 있는) 단어를 찾는 것인데, 여기에서는 car라는 핵심이 되는 단어를 찾을 수 있었습니다.
하지만 "a freind in need is a friend indeed"라는 문서에 대해 TF를 구하면 문제가 발생하게 됩니다.
TF를 구하면 불용어인 'a'가 2/8로 문서와 가장 연관성이 큰 'friend'와 같은 값을 가지게 됩니다.


IDF = LOG(Total # of Docs / # of Docs with the term in it)
*# means Number
IDF는 위 식과 같이 구할 수 있는데요, 예시를 한 번 보겠습니다. 아래 사진과 같이 A,B 두 문장(/문서)이 있는 경우 유니크 한 단어는 총 10개가 있습니다. 이제 각 단어별로 IDF 값을 구하는데요, 'a'의 경우 a가 들어간 문서가 총 2개가 있으니 분모는 2가 되고, 전체 문서의 개수가 2이니 분자도 2가 됩니다. 그러면 IDF는 LOG(2/2)이므로 0이 됩니다. (분모가 0이 되는 경우를 방지하기 위해 분모에 1을 더해 구하기도 합니다)
그럼 이제 각 문서의 각 단어별로 TF에 IDF값을 구해 TF*IDF 값을 구할 수 있게 됩니다.
TF*IDF 방식을 활용하면 아래 사진과 같이 A/B 문서와 가장 연관성있는 단어는 각각 'car', 'friend'로 나오게 됩니다. 모든 문서에서 자주 쓰이는 불용어들로 인해 불용어가 각 문서와 가장 연관있는 단어로 뽑히는 경우의 한계를 막을 수 있게 되는 것입니다.
클러스터링을 통해 유사한 데이터끼리 묶기
참고) https://hoonzi-text.tistory.com/19
-작성 대기-
'🥐데이터분석' 카테고리의 다른 글
| [토픽모델링] 논문 2개 리뷰; 스마트TV & OTT 온라인 리뷰 데이터 관련 (0) | 2022.06.14 |
|---|---|
| [토픽 모델링] LDA(Latent Dirichlet Allocation) 개념 설명👀 (0) | 2022.06.07 |
| [토픽 모델링] 기본 개념 이해하기 😎 (0) | 2022.06.06 |
| 다중회귀분석 R-squared 가 낮아도(0.2, 0.3) 괜찮을까? (0) | 2021.09.14 |
| 분류모델 성능평가 지표 : Confusion Matrix (0) | 2021.09.11 |