해보고 싶은 분석이 생겼습니다!
사실 우아한 형제들 면접 준비하면서 해볼까 고민했던건데..
배민의 경우 구글 앱 스토어 리뷰들이 총 20만개 정도 있는데 대충 감으로 봤을 때는 1. 배달 관련 2. 어플 사용성 관련 3. 할인 관련 이 정도인 것 같았습니다. 그런데 보다 보니 조금 더 체계적으로 어떤 종류의 리뷰들이 있는지 알아보고 싶어졌습니다 :)
🤖배달의 민족 최근 반 년 간 구글 앱스토어 voc 분석
1. 문제
: voc는 고객들의 니즈를 비교적 직접적으로 알 수 있는 중요한 창구임. 하지만 구글 앱스토어 voc 개수가 많아서 일일이 분류하기가 힘듦.
2. 솔루션
: 위와 같은 상황에서 자주 활용되는 텍스트 마이닝 기법 중 하나인 토픽 모델링을 활용해 리뷰의 주요 토픽들을 확인
3. 기대효과
: voc에서 확인할 수 있는 고객들의 주요 pain point 및 니즈를 파악하고, 이에 대한 솔루션을 제시해 고객 만족도를 높일 수 있도록 함
4. 진행순서
1) 토픽 모델링 공부 ✅
2) 배민 구글 앱스토어 크롤링
3) 기법 적용 및 해석
3) 인사이트 도출
토픽 모델(Topic Model)이란?
토픽 모델은 크게 두 가지 형태의 결과물을 얻을 수 있습니다.
1. 문서의 집합(Corpus)에서 토픽 K개를 만들고, 각 토픽에 단어들이 할당되는 구조로 토픽 K개를 얻을 수 있습니다.
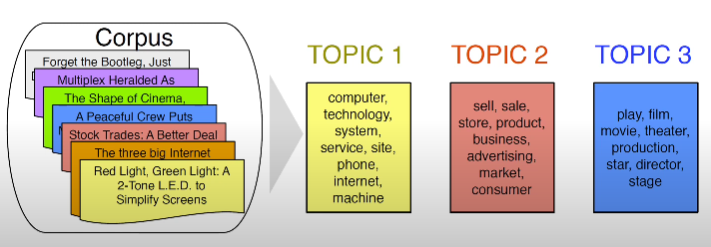
2. 개별 문서가 어느 토픽을 많이 포함하고 있는지 알 수 있습니다(각 토픽이 어느 정도의 비중을 차지하는지 알 수 있음).
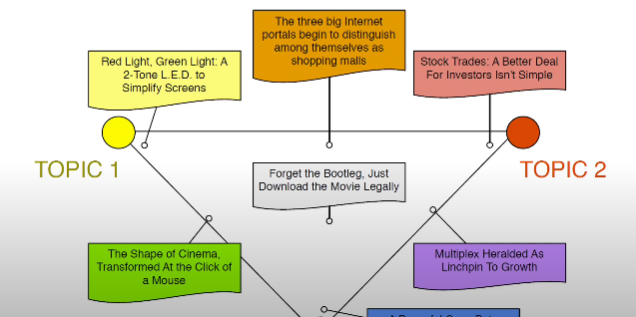
구체적으로 어떤 것들을 할 수 있을까?
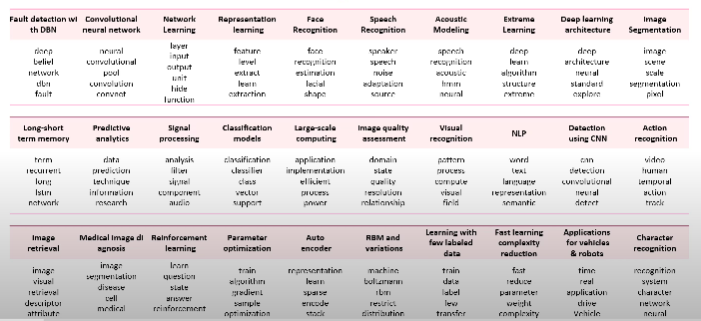
1. Topic Extraction
아래 사진은 토픽 모델링을 활용해 'Deep Learning' 관련 30개 토픽을 발견한 모습입니다. 각 토픽별로 빈도가 높은 상위 5개 단어들이 적혀있습니다. 'Face Recognition' 토픽에는 face, recognition, estimation 등의 단어가 포함되어 있습니다. 이 때 중요한 건 각 토픽에 대한 이름을 붙이는 건 연구자의 몫이라는 것! 클러스터링처럼 묶여있는 단어들만 나올 뿐 토픽을 붙이는 건 도메인 지식을 바탕으로 진행해야 합니다!
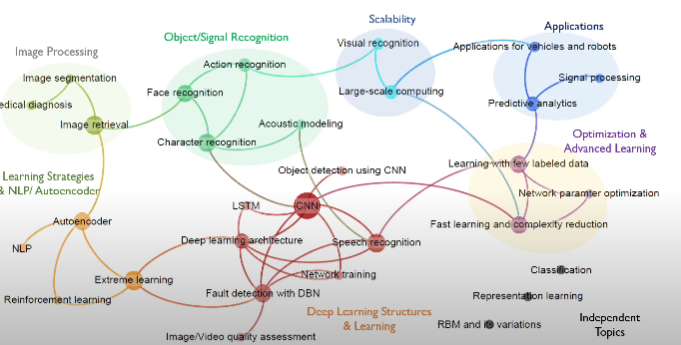
2. Relation between Topics
각 토픽들은 단어만큼의 차원으로 이루어진 연속형 벡터로, 이 특성에 따라 토픽 간 유사성을 파악할 수 있습니다.
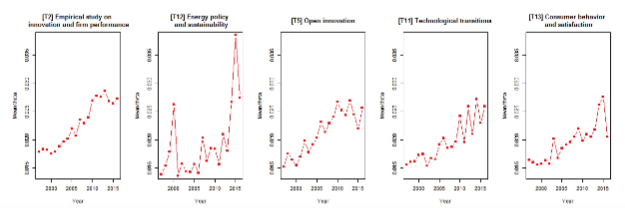
3. Topic Trend Analysis
각 연도별로 각 토픽들이 전체에서 어느 정도의 비중을 차지하고 있는지 알 수 있습니다. 회귀선(추세선)을 구하고 이 값(베타값)이 유의미하다면 해당 토픽의 인기가 점점 높아/낮아지고 있다라고 말할 수 있습니다.
이외에도 특정 잡지/콘텐츠와 유사한 잡지를 찾아내는 데에도 활용이 가능하다고 합니다.
확률적 토픽 모델(Probabilistic Topic Model)이란?
토픽 모델 종류 중에서 확률적 토픽 모델에 대해 알아봅시다. 토픽 모델링에서 가장 많이 쓰이는 LDA도 여기에 속합니다.
- 각 document는 토픽들의 확률분포이다.
- 토픽이 총 3개가 있다라고 할 때, 첫번째 document는 토픽1의 비중이 0.5, 토픽2의 비중이 0.2, 토픽3은 0.3 이렇게 나타낼 수 있습니다. 마찬가지로 나머지 document들도 각 토픽들의 비중으로 나타낼 수 있습니다.
- 즉, 토픽들의 분포로서 각 document의 핵심을 표현할 수 있습니다.
- 토픽 하나하나는 단어들의 분포이다.
- 예를 들어, 'Education'이라는 토픽이 있는데 이 토픽은 'school', 'students', 'education' 등으로 이루어져 있습니다.
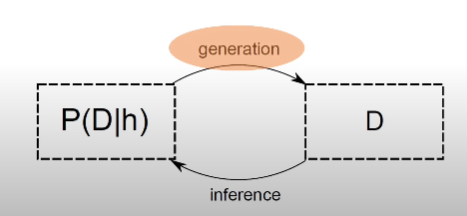
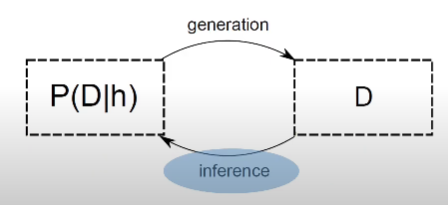
이는 통계 모델 베이스의 방법론이므로 통계적 추론(statistical inference)가 필요한데, 조금 더 쉽게 말하자면 우리가 가진 데이터로 우리가 세운 가정에 최대한 맞도록 하는 것입니다. 이런 방식을 Generative Approach라고 합니다.
여기서 중요한 개념은 '조건부 확률'입니다. P(D|h)에서 h는 hypothesis로 우리의 가정을 의미하고, D는 데이터 즉, document들의 집합입니다. 우리는 '특정 문서 생성 프로세스(h, hypothesis)를 통해 문서가 만들어진 것이다'라는 믿음을 가지고 있습니다. 우리가 해야하는 일은 통계적 추론입니다. P(h|D)이 최대화되도록 해 우리가 가정한 확률모형의 파라미터를 구하는 과정이지요. 우리가 가정한 문서 생성 프로세스란 확률모형이며 우리가 가진 데이터들로 이 모형의 파라미터를 추정하는 것은 '이 파라미터가 우리의 데이터가 우리가 가정한 프로세스에서 나왔을 확률을 최대로 한다'는 것을 의미합니다.
'🥐데이터분석' 카테고리의 다른 글
| [배민 앱 VOC분석] 리뷰 군집화/클러스터링(예행연습) (0) | 2022.06.08 |
|---|---|
| [토픽 모델링] LDA(Latent Dirichlet Allocation) 개념 설명👀 (0) | 2022.06.07 |
| 다중회귀분석 R-squared 가 낮아도(0.2, 0.3) 괜찮을까? (0) | 2021.09.14 |
| 분류모델 성능평가 지표 : Confusion Matrix (0) | 2021.09.11 |
| 중심극한정리(Central Limit Theorem), 신뢰구간(Confidence Interval) (0) | 2021.09.10 |